Scrapy是一个强大的Python网络爬虫框架,它可以帮助用户快速高效地从互联网上获取所需的数据。Scrapy的优势主要体现在以下几个方面:
强大的异步处理能力
Scrapy采用异步处理的方式,可以同时处理多个请求和响应,提高了爬取效率。同时,Scrapy还支持多线程和分布式爬取,可以进一步提高爬取效率。
灵活的数据提取方式
Scrapy提供了多种数据提取方式,包括XPath、CSS选择器、正则表达式等,用户可以根据不同的需求选择适合的提取方式。此外,Scrapy还支持自定义的数据提取方式,用户可以根据自己的需求进行定制。
可扩展性强
Scrapy的架构设计非常灵活,用户可以根据自己的需求进行定制和扩展。Scrapy提供了丰富的插件和中间件,用户可以根据需要进行选择和配置。
支持多种存储方式
Scrapy支持多种数据存储方式,包括CSV、JSON、XML、MySQL、MongoDB等,用户可以根据自己的需求选择适合的存储方式。
可视化界面
Scrapy提供了可视化界面Scrapy Shell,可以帮助用户更加直观地了解爬虫的运行情况,调试爬虫代码。
社区活跃
Scrapy是一个开源项目,拥有庞大的社区支持。用户可以在社区中获取相关的技术支持和解决方案,也可以参与到Scrapy的开发和维护中。
总之,Scrapy是一个功能强大、灵活性高、可扩展性强、支持多种存储方式的网络爬虫框架,可以帮助用户快速高效地获取所需的数据。如果你需要进行网络爬虫开发,Scrapy是一个非常值得考虑的选择。
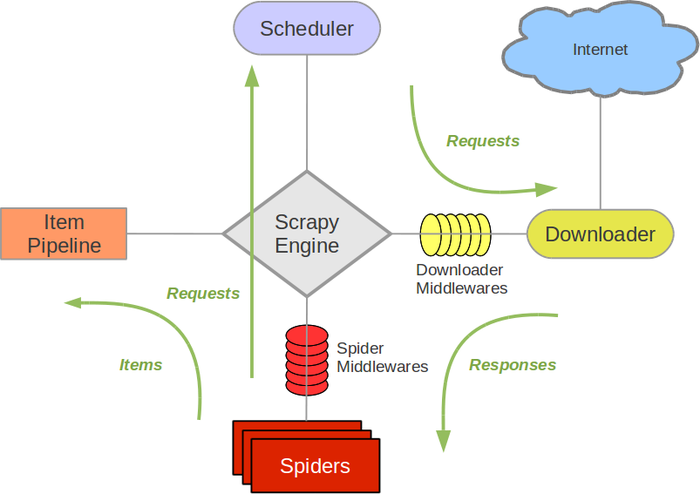
以下是Scrapy的架构图: