
-

Python 爬虫入门 Cookie 的使用
在进行 Web 爬虫时,有些网站需要登录后才能访问,这时候就需要使用 Cookie 来模拟登录状态。Cookie 是一种存储在客户端的数据,用于记录用户的登录状...
-
Python 爬虫入门URLError 异常处理
在 Python 爬虫中,由于网络环境的不稳定性,常常会出现各种异常情况,例如网络连接失败、服务器错误等。其中,URLError 是最常见的异常之一。在本文中,...
-
Python爬虫入门之Urllib库的基本使用
Urllib是Python内置的HTTP请求库,提供了一系列用于操作URL的函数,包括从网页中获取数据、修改HTTP请求头等。下面是Urllib库的基本使用方法...
-
超级简单的Python爬虫教程,帮助初学者入门
安装Python和相关库首先,你需要安装Python和相关的库,例如requests、beautifulsoup4和lxml。你可以使用pip命令来安装这些库,...
-
-
利用Scrapy进行爬虫开发指南清单
Scrapy是一个基于Python的开源网络爬虫框架,具有高效率、易扩展、易维护等特点,常用于大规模数据抓取。以下是利用Scrapy进行爬虫开发的指南清单:安装...
-
python爬虫进行Web抓取LDA主题语义数据分析报告
什么是网页抓取?从网站提取数据的方法称为网络抓取。也称为网络数据提取或网络收集。这项技术的使用时间不超过3年。为什么要进行网页爬取?Web抓...
-
爬取数据时,高版本 App 如何进行抓包
我们都知道 iphone 和低版本 Android 抓包,只需要设置代理和配置证书就可以顺利抓包但是升级了 targetSdkVersion 到 28 后发现,...
-
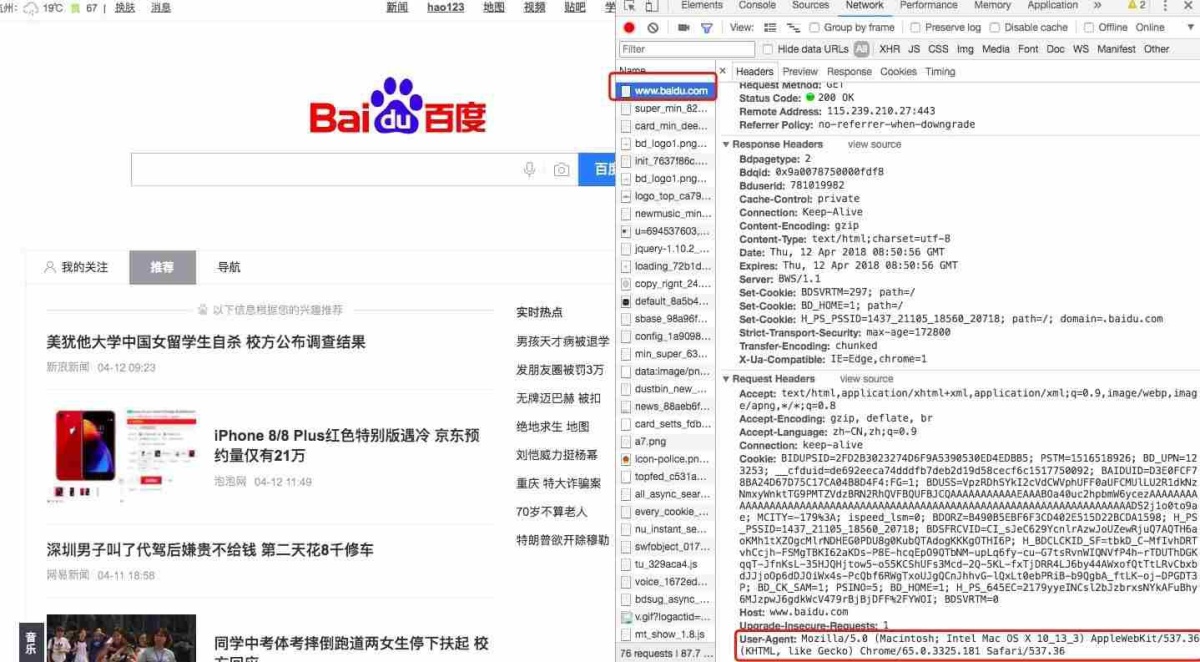
Python反爬虫伪装浏览器进行爬虫
对于爬虫中部分网站设置了请求次数过多后会封杀ip,现在模拟浏览器进行爬虫,也就是说让服务器认识到访问他的是真正的浏览器而不是机器操作简单的直接添加请求头,将浏览...
-
栏目索引
阅读排行榜