
-

Python中 BS4解析库用法详解
BeautifulSoup4(简称BS4)是Python中常用的HTML/XML解析库,可以用于从网页中提取数据。以下是BS4的一些常用用法:导入库:使用BS4...
-
Python中 json模块常用方法
Python的json模块可以用于处理JSON格式的数据,包括解析JSON数据和生成JSON数据。以下是json模块的一些常用方法:json.loads():将...
-
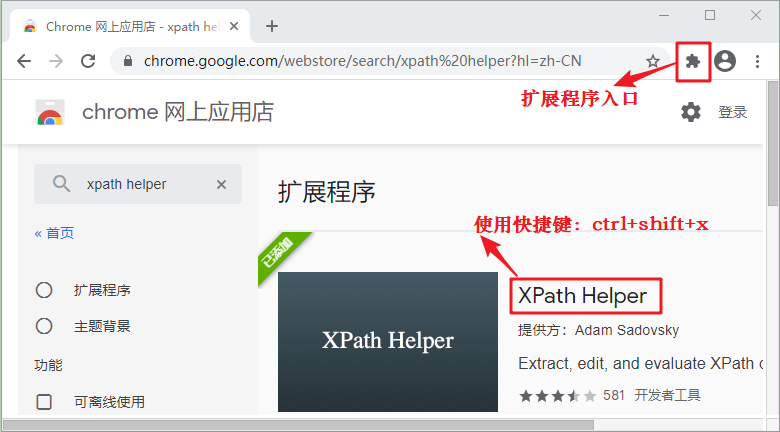
-

Fiddler抓取内容自动保存本地
Fiddler是一个流行的Web调试工具,它可以用于抓取HTTP请求和响应,并进行流量分析。Fiddler默认情况下不会将抓取的内容保存到本地,但是可以通过以下...
-
-
linux上如何安装mitmproxy
在Linux上安装mitmproxy,可以通过以下步骤完成:安装pipmitmproxy是一个Python程序,需要使用pip来安装。如果你的Linux系统中没...
-
-
深入selenium三种等待方式使用
Selenium是一个流行的自动化测试工具,它可以用于模拟用户在Web浏览器中的操作。在使用Selenium时,我们经常需要等待某些元素出现或某些操作完成。Se...
-
深入selenium模块基础操作
Selenium是一个用于Web应用程序测试的工具,可以模拟用户在浏览器中的操作,例如点击、输入、滚动等。以下是Selenium模块的一些基础操作:安装Sele...
-
python爬虫网页解析之parsel模块
Parsel是一个基于XPath和CSS选择器的Python爬虫解析库,它可以用于从HTML或XML文档中提取数据。与BeautifulSoup等解析库不同,P...
栏目索引
阅读排行榜